特別講義DS Ch4 Pythonことはじめ
資料
Pythonことはじめ
この章では,Pythonの基礎の基礎を学習します. 本講義はプログラミング自体の学習を対象としているわけではないので, 講義内で必要な技能を紹介するのみに留めます.
基本的には,公式のPythonチュートリアルの内容で必要十分ですので,そちらにそって学習を進めます. より詳しい内容を勉強したい場合には,プログラミングの講義を履修するか, 千葉商科大学IEEESB などに参加するのが良いかと思います.
今回は取り敢えず,以下の作業を自分で行いながら,Pythonの体験をしてみましょう.
REPLを使ってみよう
プログラムの対話環境全般をREPL (Read Eval Print Loop)と呼びます. 長いプログラム(スクリプト)を書かなくても対話的にプログラムを実行することができます.
Pythonには複数のREPLがあり,iPython, jupyternotebook, Google Colaboratoryなどがあります.ここではとりあえず,iPythonを利用します. 他のものについても,後ほど出てきます.
プロジェクトのディレクトリ内で uv run python と入力することで,Python の REPL が立ち上がります. uv run はプロジェクトの仮想環境を自動で同期してから実行するため, uv add で追加したパッケージもそのまま利用できます.
> uv run python
Python 3.11.9 (main, Aug 14 2024, 04:18:20) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>uv python install 3.11.9 --default によってグローバルに python コマンドが使えるようになっている場合は,python だけでもREPLが立ち上がります. ただしこの場合, uv add で追加したプロジェクトのパッケージは読み込めません. プロジェクト内のパッケージを使いたい場合は必ず uv run python を使いましょう.
また, uvx ipython でIPythonという高機能なREPLを利用することも可能です.
> uvx ipython
In [1]:uvx は uv tool run のエイリアスで,一時的な隔離環境にパッケージをインストールして実行するコマンドです. プロジェクトには追加されないため,ちょっとした電卓的な利用に便利です. プロジェクトの依存パッケージ(uv add したもの)を使いたい場合は uv run python を使ってください.
プログラムを書いてEnter Keyを押すとその行のプログラムが実行されます.
>>> 1 + 1
2終了するには,exit()と入力します.
~/Desktop 1m 7s
Python 3.10.11 (v3.10.11:7d4cc5aa85, Apr 4 2023, 19:05:19) [Clang 13.0.0 (clang-1300.0.29.30)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> 1 + 1
2
>>> exit()
~/Desktop 1m 7sコメントアウト
REPL上でもスクリプトでも,#を先頭につけると,その行はコメントとして扱われます.
ただのコメントであり,プログラムとしては何も実行されません.
>>> # これはコメント何も起きない
>>>データ型
第1回の検査に関する説明で軽く触れましたが, プログラミングで扱うデータはコンピュータのメモリ上に数値の羅列として存在します. それらの数値に人間が解釈可能な意味を与えたものをデータ型といいます.
Pythonで最初から準備されているデータ型(組み込み型)には以下のようなものがあります. 詳細はこのあと順番に見ていきますので, こんなものがあるということだけ,頭に入れておきましょう.
Pythonのデータ型(一部)
数値型:数値を表す
- 整数(
int) - 浮動小数点数(
float) - 複素数(
complex)
- 整数(
文字列型(
str):文字を表すリスト(
list):いくつかのデータをまとめたものタプル(
tuple):データの組み合わせ辞書型(
dict):keyとvalueからなる辞書を表す真偽値(
bool):正しいか正しくないかなどを表す
数値型(Pythonを電卓として使う)
REPLの動きに慣れるために,電卓で行うような簡単な計算をREPL上で行いましょう.
電卓で行う計算なので,ここで扱うデータ型は数値型になります.
Pythonにおける数値型には整数を表すint,小数を表すfloat,複素数を表すcomplexがあります. 本資料では,その内intとfloatについて扱います.
基本的には1や100のような整数を書けばint型として認識され,1.0や100.3のように小数点をつけるとfloat型として認識されます.
>>> 1
1
>>> 1.0
1.0Pythonではtype()の丸括弧の中にデータを記述することで特定のデータのデータ型を確認することができます.
>>> type(1)
<class 'int'>
>>> type(1.0)
<class 'float'>整数や後述の文字など変換可能なデータ型から,int型へ変換するにはint()の中に,そのデータを書きます. float型に変換するには,float()を使います.floatからintへの変換では,小数点以下が切り捨てられます.
>>> int(4.9)
4
>>> float(2)
2.0
>>> float("2")
2.0Pythonでは複数の数値型が混ざった計算に対応しています. 基本的に,特定の計算で複数の数値型が混じっている場合には, int型はfloat型に,float型はcomplex型に自動で拡張されるので本講義の範囲ではそれほど意識する必要はありません.
簡単な計算に用いる記号は以下のとおりです.
| 計算 | 記号 |
|---|---|
| 足し算 | + |
| 引き算 | - |
| 掛け算 | * |
| 割り算 | / |
| 整数除算 | // |
| 剰余(余り) | % |
| 累乗 | ** |
| 絶対値 | abs() |
| 整数変換 | int() |
| 小数変換 | float() |
実際の計算は以下のようになるはずです.
計算は普通の電卓と同じような感覚で使えます.
>>> # 足し算
>>> 1 + 1
2
>>> # 引き算
>>> 10 - 5
5
>>> # 掛け算
>>> 2 * 3
6
>>> # 割り算
>>> 100 / 5
20.0計算には順序があり丸括弧 ()で囲うことで計算する順番を変えることができます.
>>> (50 - 5 * 6) / 4
5.0
>>> 50 - 5 * 6 / 4
42.5マイナスの数は数値の前に-をつけます
>>> 10 + -5
5割り算の商と余りは//や,%で計算できます.
>>> # 整数除算(余りを表示しない)
>>> 6 // 4
>>> 1.0
>>> # 剰余(余り)
>>> 17 % 3
2
>>> 5 * 3 + 2
17同じ数字をX回掛けたものを累乗といい,**といいます. 2 ** 3 = 2 * 2 * 2
>>> # 累乗
>>> 2 ** 2
4
>>> 2 ** 3
8abs() の中に数値を入れることで絶対値が計算できます
>>> abs(4)
4
>>> abs(-4)
4Exercise SLDS4-1
REPL を使った基本計算
以下の計算をREPLを使って自分でしてみましょう. Pythonの計算になれることが目的ですので,どのように計算したかを説明できるようにしましょう.
飴が40個あります.7人で同じ数ずつ分けると1人分は何個で何個あまりますか?
底辺5cm,高さ4cmの三角形の面積はいくつですか?
2の8乗はいくつですか?
累乗と掛け算の計算順序を丸括弧を使った計算で確かめてください.
回答例
# 飴 40 個 を 7 人で同じ数ずつ分ける
>>> 40 // 7
5
>>> 40 % 7
5
# → 1 人 5 個, 余り 5 個
# 底辺 5cm, 高さ 4cm の三角形の面積
>>> 5 * 4 / 2
10.0
# → 10 cm²
# 2 の 8 乗
>>> 2 ** 8
256
# 累乗 (**) と掛け算 (*) の計算順序: 累乗の方が優先順位が高い
>>> 2 * 3 ** 2
18
>>> (2 * 3) ** 2
36
>>> 2 * (3 ** 2)
18
# → 括弧なしでは 2 * (3 ** 2) と同じ変数と代入
値に名前をつけることを代入といい,名前のついた値を変数といいます. = の左側に付けたい名前,右側に値を書きます.
プログラムでは,データはコンピュータの記憶領域(メモリ)に格納されています. メモリは,1バイト(8bit, 1bit は0/1の値)ごとにアドレスという連番がついています.

>>> x = 10変数を宣言するということは,このアドレスにデータを割り当てることを意味します.
x = 10という変数が4バイト利用するとしたら以下のようにアドレス 201 から204 に 10という数字(int)を割り当てるイメージです.
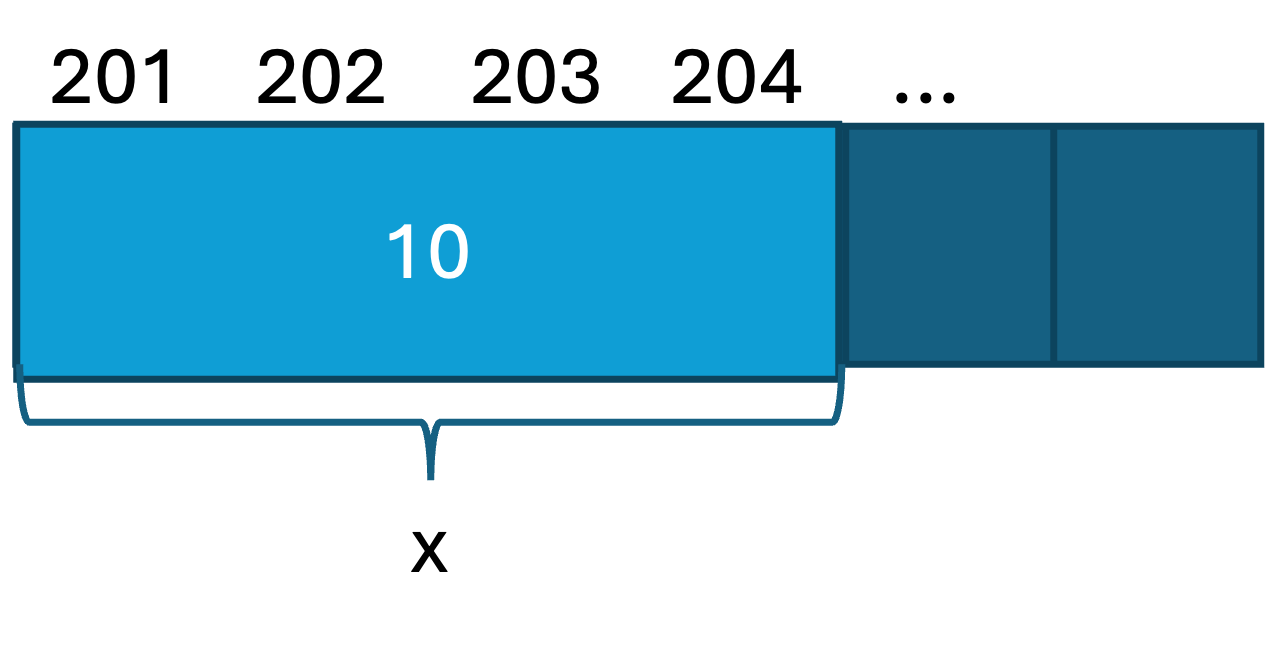
xのアドレスはid(x)で確認できます.
>>> id(x)
4438639120y = x と変数に別の名前を宣言する場合は,同じ場所が参照されます.
>>> y = x
>>> id(x)
4438639120
>>> id(y)
4438639120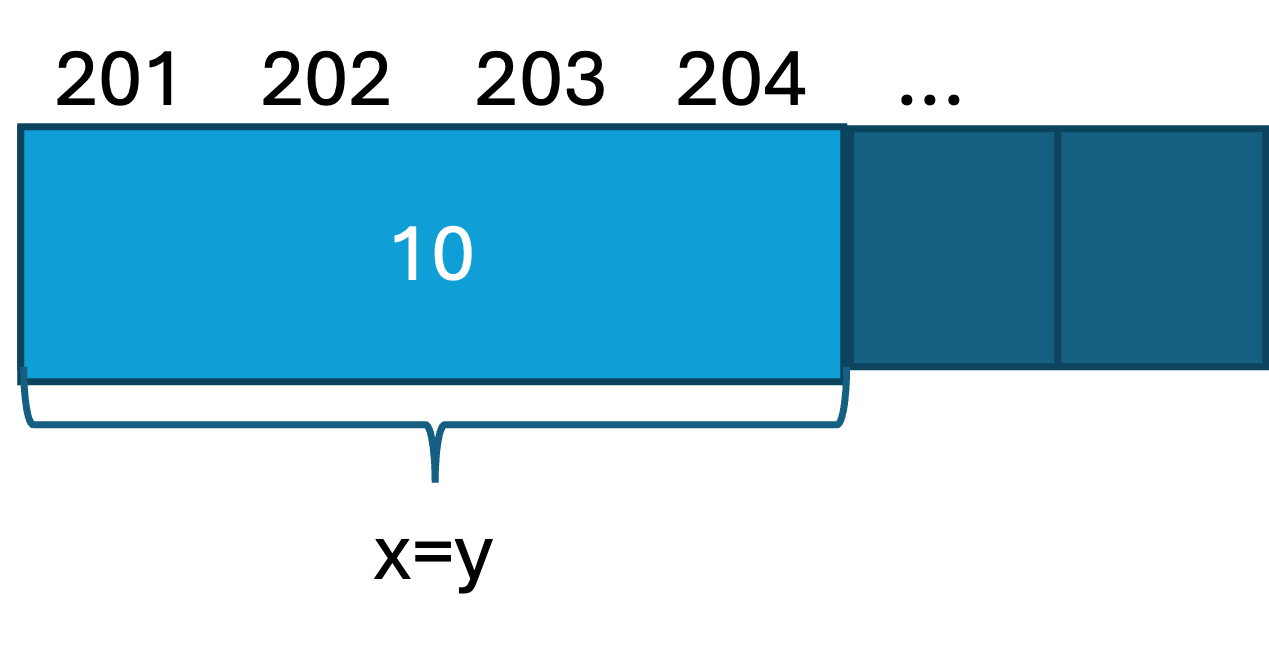
x=15と再度代入する(再代入)と,新しくメモリが確保されます.
その際に,xをコピーしていたyの値も変わることに注意しましょう.
>>> x = 15
>>> id(x)
4438639280
>>> id(y)
4438639280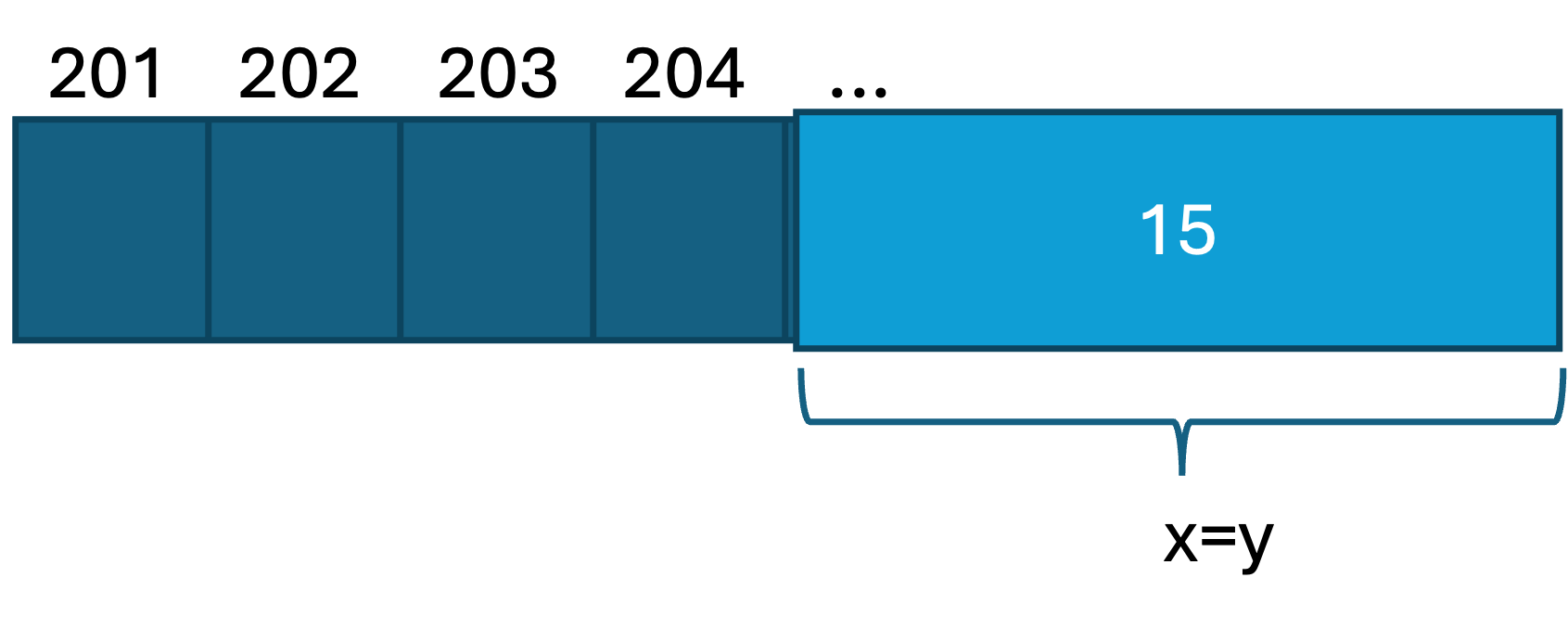
数値の場合にはyに再代入しても,xの値は変わりません.
>>> x = 10
>>> y = x
>>> id(x)
4438639120
>>> id(y)
4438639120
>>> y = 15
>>> y
15
>>> x
10
>>> id(x)
4438639120
>>> id(y)
4438639280この挙動は,後に出てくる配列では,異なるので注意が必要です.
変数に名前をつける際には,以下の点に注意しましょう.
小文字で始まる英数字を使う
複数の単語を使うときは
_(アンダーバー)でつなげる英語で名前をつける
nagasaではなくlengthnamaeではなくname
長くなっても良いので他の人が見たときに意味がわかる名前をつける
- 三角形の高さを表したいとして
xやhなどの一文字よりもheightのほうが良い- 他にも高さを表す変数が登場するなら
triangle_heightのほうがより分かりやすい
- 三角形の高さを表したいとして
>>> # 長方形の面積を求める
>>> width = 20
>>> height = 5
>>> area = width * height
>>> area
900
>>> #定義されていないものはエラーがでます
>>> space
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'space' is not definedExercise SLDS4-2
変数を使った BMI 計算
- 変数を利用して以下の猫型ロボットのBMIを計算してください
- BMI = 体重(kg)÷身長(m)の2乗
- 猫型ロボットの身長 129.3cm
- 猫型ロボットの体重 129.3kg
回答例
height_cm = 129.3
weight_kg = 129.3
height_m = height_cm / 100
bmi = weight_kg / (height_m ** 2)
print(bmi)
# → 77.317... (体重 / 身長(m) の 2 乗)代入演算子
代入は=でつなげる以外にもいくつかのパターンがあります.
まずは,普通に変数に数値を代入してみます.
>>> x = 1
>>> x
1
>>> x = 2
>>> x
2このように具体的な値を=の右側に記入するのは直感的に分かりやすいのですが,pythonのプログラムを見ていると,左右に同じ変数名が登場する場合があります.
>>> x = 1
>>> x = x + 1
>>> x
2これは,右側に登場するxは過去のxを表しており,左側に登場するxは,過去のxを利用して作られた新しいxであると解釈しましょう.
上の例では,x=1という過去の変数を使って, x(=1) + 1という新しいxを作っています.
これは自己代入と呼ばれ,数学や関数型言語における再帰とは異なり,手続き型言語独特の記法なので注意しましょう.
足し算+を使った自己代入は省略して, x += 1のように書けます. これは x = x + 1の省略形で複合代入演算子といいます.
同様に,引き算-=,掛け算 *=, 割り算 /=などの代入演算子も存在します.
>>> x = 10
>>> x -= 5
>>> x
5
>>> x *= 5
>>> x
25
>>> x /= 5
>>> x
5文字列型
ここまでは,数値のみを扱ってきましたが,Pythonには数値以外にもいくつものデータ型が存在します.
次に, 文字を表す文字列型(str)の利用法について見ていきましょう.
文字列型は,文字を""(ダブルクオーテーション),あるいは''(シングルクォーテーション)で囲みます.
>>> "イヌ"
'イヌ'
>>> 'ネコ'
'ネコ'
>>> type('ネコ')
<class 'str'>三連引用符"""で囲むことで複数行書くことができます.
>>> """ あ
... い
... う"""
'あ\nい\nう'\nは改行を表しています.
>>> print('あ\nい\nう')
あ
い
う文字列の演算
文字列は+で連結,*で反復させることができます.
>>> name = '太郎'
>>> '私は' + name + 'です!'
'私は太郎です!'
>>> name * 3
'太郎太郎太郎'変数を文字列の中で使いたいときには,上の例のように+で連結することもできますが,変数が文字列型ではないときには,str()を利用して文字列型に変換してから,結合する必要があります.
>>> cat_num = 10
>>> type(cat_num)
<class 'int'>
>>> #そのまま文字列と結合するとエラーが出る
>>> '私はネコを' + cat_num + '匹飼っています.'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
>>> #str()を利用して文字列に変換する
>>> '私はネコを' + str(cat_num) + '匹飼っています.'
'私はネコを10匹飼っています.'また,変数の値を文字列の中で利用する場合にはstr()や+を利用して結合する以外にもf'文字列'という記法を利用することができます.文字列の前にfと書くと,文字列内の{変数名}の部分が変数の値に変更されます.
>>> f'私はネコを{cat_num}匹飼っています.'
'私はネコを10匹飼っています.'{変数名}の部分には式を入れることも可能です.
>>> f'私はネコを{cat_num*10}匹飼っています.'
'私はネコを100匹飼っています.'文字列が代入された変数の後ろに[]をつけて,番号を[]の中に入れると,指定した番号番目の文字が取得できます. このような[]で指定する数字をindexといいます.
Pythonという文字に対して,indexは以下のように振られています.
-をつけて後ろから数えることもできます.
| 文字列 | P | y | t | h | o | n |
|---|---|---|---|---|---|---|
| 前から | 0 | 1 | 2 | 3 | 4 | 5 |
| 後ろから | -6 | -5 | -4 | -3 | -2 | -1 |
Pythonの文字列は,最初の文字を0番目と数えるので注意しましょう.
>>> word = 'Python'
>>> word[0]
'P'
>>> word[5]
'n'
>> word[-6]
'p'インデックスの[]の中で,[Start:End]のようにはじめと終わりのインデックスを指定することで,文字列の1文字ではなく,部分的な文字列を取得することもできます. これをスライスといいます.
終わりは,一つ手前までになるので注意しましょう.
>>> word[0:2]
'Py'
>>> word[2:5]
'tho'はじめか終わりのインデックスを省略すると,以前/以降の全てという意味になります.
>>> word[:4] #0から4まで
'Pyth'
>>> word[2:] #2から最後まで
'thon'Exercise SLDS4-3
文字列のスライス操作
- 演習1
'abcdefg' から 'cde'をスライスで抜き出してください.
- 演習2
x = 'abcdefg'と定義して, xに操作を加えて'abfg'を作ってください.
- 演習3
x = 'abcdefg'と定義して, xに操作を加えて'bbbeee'を作ってください.
回答例
x = 'abcdefg'
# 演習 1: 'cde' を抜き出す (index 2-4)
print(x[2:5]) # 'cde'
# 演習 2: 'abfg' を作る
print(x[0:2] + x[5:7]) # 'abfg'
# 演習 3: 'bbbeee' を作る
print(x[1] * 3 + x[4] * 3) # 'bbbeee'リスト
複数の値をまとめるデータ型の一種にリスト型があります. コンマで区切って角括弧の中に複数の値を書くことで,ひとまとまりのデータを作れます. リストの中身一つ一つを要素といいます.
>>> squares = [1,4,9,16,25]
>>> squares
[1,4,9,16,25]リストは文字列と同じ様に,インデックスやスライスで要素を取得できます.
>>> squares[0]
1
>>> squares[-1]
25
>>> squares[-3:]
[9,16,25]リストの演算
リストも+で連結,*で反復させることができます.
>>> [1,2,3] + [4,5,6]
[1,2,3,4,5,6]
>>> [1] * 3
[1,1,1]
>>> [1,2] * 3
[1,2,1,2,1,2]リストはインデックスやスライスで指定した要素に値を再代入して変更することができます.
>>> animals = ['cat','dog','bird']
>>> animals[1] = 'mouse'
>>> animals
['cat','mouse','bird']
>>> animals[1:] = ['fish','pig']
>>> animals
['cat','fish','pig']リストは,数値などとは変数に別の名前をつけたときの挙動が異なるので注意が必要です.
数値や文字列は,別の名前をつけた変数に再代入した場合もとの変数は,変更されません.
>>> cat = 'cat'
>>> cute_cat = cat
>>> cute_cat = 'cute_cat'
>>> cat
'cat'
>>> cute_cat
'cute_cat'cute_catを変更してもcatは変わりません. 代入の説明箇所で見たように,数値などの変数の場合は,cute_catにはcatの値が渡されており,値が同じ場合には同じアドレスを参照するが,値が変更された場合には,
新しいメモリが確保されます.
しかし,リストは別名の変数を変更すると元の変数の値も変更されます.
>>> animals = ['cat','fish','pig']
>>> species = animals
>>> species[0] = 'horse'
>>> animals
['horse', 'fish', 'pig']
>>> species
['horse', 'fish', 'pig']animalの別名speciesを変更するとanimalも変更されています. これは,配列などは新しい名称の変数に,値ではなくアドレスを渡していることによります.どちらの変数もずっと同じアドレスを参照しつづけるため,片方が変化すると同じアドレスを参照しているもう片方の値も変わります.
>>> id(animals)
4441753024
>>> id(species)
4441753024
>>> species[0] = 'cat'
>>> id(species)
4441753024しかし,インデックスやスライスによる要素の変更ではなく,全体を再代入した場合には新しいアドレスが割り当てられます.
>>> species = ['a','b','c']
>>> id(species)
4441834752同じ値を持つが異なる場所を参照するリストを作りたい場合には,copy()を利用します.
>>> animals = ['cat','fish','pig']
>>> species = animals.copy()
>>> id(animals)
4441764160
>>> id(species)
4441798208
>>> species[0] = 'dog'
>>> animals
['cat', 'fish', 'pig']
>>> species
['dog', 'fish', 'pig']このような挙動は今後出てくるpandasなどの配列でも同様なので,注意が必要です.
append()というメソッドを使って,リストの末尾に要素を追加することができます.
>>> animals
['cat','fish','pig']
>>> animals.append('dog')
>>> animals
['cat','fish','pig','dog']リストの長さ(要素数)を知りたい場合には,len()関数を利用します.
>>> animals
['cat','fish','pig','dog']
>>> len(animals)
4メソッド,関数という言葉が説明無しに突然でてきました.
これらの違いについて理解するには段階が必要なため,後に説明します.
ここでは,変数などの後ろに変数.f()の形で.を利用してつけるものをメソッド,単独でf()のように利用するものを関数ということだけ覚えておきましょう.
なお,いずれも()の中に値や変数を書いたり書かなかったりしますが,その意味についても後ほど扱います.
リストはリストも要素にすることができます. このようなリストを多重リストと呼びます.
>>> x = [1,2,3]
>>> y = [4,5,6]
>>> z = [x,y]
>>> z
[[1,2,3],[4,5,6]]
>>> z[1]
[4,5,6]
>>> z[0][1]
2Exercise SLDS4-4
リスト操作 (len / スライス / 更新 / append)
xs = [[1,2,3],[4,5,6],[7,8,9]] というリストを作り,以下の操作を行ってください.
xsの長さを求めるスライスを使って以下を抽出する
[[4,5,6],[7,8,9]][[1,2,3]][[7,8,9]][8,9]
[4,5,6]を[-4,-5,-6]に更新する1を-1に,9を-9にする[7,8,-9]のあとに,[10,11,12]を追加する
回答例
xs = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 長さ
print(len(xs)) # 3
# スライス
print(xs[1:]) # [[4,5,6], [7,8,9]]
print(xs[:1]) # [[1,2,3]]
print(xs[2:]) # [[7,8,9]]
print(xs[2][1:]) # [8, 9]
# [4,5,6] を [-4,-5,-6] に
xs[1] = [-4, -5, -6]
# 1 → -1, 9 → -9
xs[0][0] = -1
xs[2][2] = -9
# 末尾に [10,11,12] を追加
xs.append([10, 11, 12])
print(xs)
# [[-1, 2, 3], [-4, -5, -6], [7, 8, -9], [10, 11, 12]]タプル
Pythonにはリスト以外にも複数のデータ型の組み合わせを表すデータ型が存在します. タプルは,データの組を表すデータ型であり,()の中に,で区切ってデータを入れることでリストのようにデータを格納することができます.
タプルも複数のデータをまとめることができます.
しかし, リストのように扱うことは推奨されません. (後に扱う関数などで返り値を複数返したいときなど)基本的に2,3個のデータの組を扱いたい場合に利用して,3個以上のデータを扱い場合にはリストなどを使うようにしましょう.
>>> name_and_age = ('Taro',10)
>>> name_and_age
('Taro', 10)タプルの値の取り出しには,同じ形のタプルに変数を格納することで値を取り出すパターンマッチが良く利用されます.
>>> (name,age) = name_and_age
>>> name
'Taro'
>>> age
10インデックスによる値の取得も可能です.
>>> name_and_age[0]
'Taro'
>>> name_and_age[1]
10ただし,インデックスを利用した要素の変更はできません.
>>> name_and_age[0] = 'Hanako'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment辞書型
名前とその意味, 商品と在庫数,日本語名と英語名など,特定のデータに対応する別のデータの組み合わせを沢山扱いたい場合には,辞書型(dict)が利用されます. 辞書型はkeyとvalueと呼ばれるデータの組み合わせからなります.
辞書型のデータは,{key1:value1,key2:value2,...}のように,keyとvalueの組み合わせを:で表して,{}にコンマで区切るかたちで作成します.
例えば, 学生と学生の出席回数の組み合わせを表すデータは以下のように作成されます.
>>> attendance = {'Taro':10,'Hanako':12,'Kenta':9,'Shizuka':10}
>>> attendance
{'Taro': 10, 'Hanako': 12, 'Kenta': 9, 'Shizuka': 10}dict()にkeyとvalueのタプルのリストを渡すことで生成する事もできます.
>>> attendance = dict([('Taro',10),('Hanako',12),('Kenta',9)])
>>> attendance
{'Taro': 10, 'Hanako': 12, 'Kenta': 9}特定のkeyでそれに対応するvalueを呼び出すには,keyをインデックスとして[]を利用します.
>>> attendance['Taro']
10
>>> attendance['Shizuka']
10新しいkey:valueを加える場合にも,valueを変更する場合にも,インデックスによる代入が利用できます.
>>> attendance['Taro'] = 11
>>> attendance['Taro']
11
>>> attendance['Shinzi'] = 12
>>> attendance['Shinzi']
12keyを削除するにはpop(消したいkey)メソッドを利用します.
>>> attendance.pop('Hanako')
>>> attendance
{'Taro': 11, 'Kenta': 9, 'Shizuka': 10, 'Shinzi': 12}辞書型のデータから,keyのみ,valueのみを抜き出すには,keys(),values()メソッドを利用します.
リストとして取得したい場合には,list()関数で囲みます.
>>> attendance.keys()
dict_keys(['Taro', 'Kenta', 'Shizuka', 'Shinzi'])
>>> attendance.values()
dict_values([11, 9, 10, 12])
>>> list(attendance.values())
[11, 9, 10, 12]これらの処理はリストを利用しても可能ですが,辞書型のほうが計算が速いため辞書型を利用するようにしましょう. プログラミングにおいては用途に応じて適切なデータ型を選択することが重要です.
同じような処理が可能なデータ型でも,その処理を実行するのにコンピュータが必要な計算の数や,使用するメモリの量,速度などに違いがあります.
この資料では扱いませんが,大規模なデータを扱う場合や,大量の計算を行うプログラムを書く際には,計算量を考慮してアルゴリズムとデータ構造を適切に設計する必要があります. 興味のある方は,調べてみましょう.
Exercise SLDS4-5
辞書の作成と要素追加
5種類の果物の日本語名と英語名を変換する辞書を作成し,実際に機能する様子を紹介してください.
上で作成した辞書にもう一つ果物を追加してください.
回答例
# 5 種類の果物 (日本語 → 英語)
fruits = {
"りんご": "apple",
"みかん": "orange",
"ぶどう": "grape",
"バナナ": "banana",
"いちご": "strawberry",
}
# 動作確認: 日本語キーで英語名を引く
print(fruits["りんご"]) # 'apple'
print(fruits["バナナ"]) # 'banana'
# 追加: 1 つ増やす
fruits["桃"] = "peach"
print(fruits["桃"]) # 'peach'
print(len(fruits)) # 6論理演算
それが正しいか間違っているか判別できる文を命題といいます. 命題の結果を表すものとして真(正しい),偽(間違っている)という値を用います. 真と偽を併せて真偽値といいます.
例えば,1は2より大きいという命題は,間違っているので偽となります. 人間は必ず死ぬという命題は,今のところ不老不死の人間がいないので真です.
プログラミングではこのような命題の判断がしばしば必要となるため,それらを扱うデータ型が提供されています.
真偽値を表すデータ型としてBoolがあります. BoolはTrue(真),False(偽)のいずれかです.
Pythonには命題の判定を行う演算子として,以下のようなものが準備されています.
| 記号 | 意味 |
|---|---|
> |
より大きい |
>= |
以上 |
< |
より小さい |
<= |
以下 |
== |
等しい |
!= |
等しくない |
in |
含む |
数値などの大小関係を調べるときには,比較演算子 >,>=.<,<=を利用します. 演算子の左右に数値を書くと,結果に応じて真偽値が帰ってきます.
>>> 1 > 2
False
>>> 1 < 1.5
Trueリストや文字列に特定の要素(文字列)が含まれているかは,inで判定できます.
>>> 'ab' in 'abcd'
True
>>> 1 in [3,4,5]
False値が等しいか/等しくないかを判定するには,==と!=を利用します.
>>> 4 == 4
True
>>> 'cat' != 'cat'
Falseこれ以外にもPythonにはいくつかの演算が準備されていますし,自分で作ることも可能です.
True や FalseなどのBool値は, AND(かつ),OR(または),NOTという演算で計算することができます(XORというのもあるが省略).
PythonではAND は &, OR は |, NOT は not という演算子が提供されています.
A,Bが命題だとして,A & Bは両方Trueのときに,Trueとなります. A | Bは片方どちらかがTrueのときにTrueとなります.
例えば,
1は2より大きい かつ 2は0より大きいという命題は,2は0より大きいは正しいですが,1は2より大きいが間違っているので全体として,Falseです.ネコは哺乳類である または ネコは鳥類であるという命題はネコは鳥類であるが間違っていますが全体としてはTrueです.
演算の結果は,それぞれ以下のようになります. これを真偽値表といいます. ここでは,最低限の例だけを紹介しますが,より深く理解したい人は論理学などの講義を受講しましょう.
| 命題Aの値 | Bの値 | A & B |
A | B |
|---|---|---|---|
| True | True | True | True |
| False | True | False | True |
| True | False | False | True |
| False | False | False | False |
Pythonではそれぞれの命題を丸括弧で囲んで,&,|演算子で論理演算を行うことができます.
>>> (1 > 2)
False
>>> (2 > 0)
True
>>> (1 > 2) & (2 > 0)
False
>>> (1 > 2) | (2 > 0)
Truenot は命題の否定を表しており TrueがFalse,FalseがTrueになります.notは命題の前に書きます.
>>> (1 > 2)
False
>>> not (1 > 2)
TrueExercise SLDS4-6
偶数判定と論理演算 (and / or / not)
ある値が偶数かどうかは,2で割った余りが0かどうかを判定することで判定できます.
x=101,y=202として, 以下の命題の真偽をPythonで計算してください.
- xが偶数
- yが偶数
- xが偶数かつyが偶数
- xが偶数またはyが偶数
- x + y が奇数
回答例
x = 101
y = 202
p = x % 2 == 0 # x が偶数か → False (x = 101 は奇数)
q = y % 2 == 0 # y が偶数か → True (y = 202 は偶数)
print(p) # False
print(q) # True
print(p and q) # False (x と y の両方が偶数か)
print(p or q) # True (x または y が偶数か)
print((x + y) % 2 != 0) # True (x + y = 303 は奇数)(復習)スクリプトの実行
これまでは,対話環境でプログラムを実行してきましたが,対話環境は複雑な処理には適しません.
これから,1行1行プログラムを記述して対話環境で実行するのではなく,複数行のプログラムをまとめて記述して一気に実行する方式に切り替えます. 複数行のプログラムを一つのファイルにまとめたものをスクリプトファイルと呼び, 書かれているプログラムをスクリプトといいます. 前回行ったHello Worldはスクリプトを実行していました.
Pythonのスクリプト実行の方法
テキストファイルにプログラムを書く
ファイルの拡張子を
.pyにして保存する- 講義で作成したプログラムは,あとで自分が参考にできる最高の資料です.
あとで何をやっているのか自分が理解できるように プログラムにはできるだけ沢山のコメントを付けましょう
ファイル名は,後からみて,中身が何であるかわかるよう
英数字で名付けましょうa.pyやfile.py,課題.pyなどはやめましょう
- 講義で作成したプログラムは,あとで自分が参考にできる最高の資料です.
Shell上でそのファイルが保存されている場所に移動する
python ファイル名コマンドで実行する- ※
pythonは空白の後に続くプログラムを実行するためのコマンドです.
- ※
Exercise SLDS4-7
スクリプトファイルでの出力
前回行ったHello Worldを参考に,Let's start Python programming!! と表示されるプログラムを作成しましょう. ファイル名などは適切に名付けてください.
まだ,今後沢山のスクリプトを書いていきますので,適切にフォルダなどを整理しましょう.
回答例
# letsstart.py
print("Let's start Python programming!!")実行:
$ python letsstart.py
Let's start Python programming!!エラーへの対応法とよくある間違い
これまで皆さんは1行のプログラムを記述して, REPL上で実行してきました. これから何行かに渡るプログラムを記述すると, うまくできない人が出てきます. ここでは,学生のつまずきやすいポイントとその対策について,事前に学習しておきましょう.
エラーへの対応方法
間違った手順,プログラムの記述方法でプログラムを実行すると,エラー文がTerminalに表示されます. どれだけプログラミングが得意な人でも, 完璧な作業はできません. 必ずエラーが発生します. そのような意味でも,プログラミングをするというのは,プログラムを書いて発生したエラーに対応するということでもあります.
エラーへの対応は, プログラミングにある程度習熟した人でも,Webなどで調べて解決する場合が多いです.PCやプログラミングができるということは,すべての場合をすべて記憶して対応できるということではなく,問題が起きたら自分で解決できるということを意味しています.
したがって, まず必要なのは問題が起きたら解決策を自分で調べることです.
解決方法を調べるためには,検索するためのワードとして,機能や名称を知っていることが重要です. 例として, Excelのフィルター機能の存在を知っていれば, Excel フィルター 使い方などで検索することができます.しかし,Excelも,フィルターも知らなければ,調べることすらできません.
すべての概念や機能を最初から完全に理解する必要はありませんが,概念の存在や名称を覚えるようにしましょう. そのためにも自分のメモやチートシートを作成,整理しておくことが重要です.
プログラミングの学習において, 何かが間違っている場合には, Terminalにエラー文が表示されます. Pythonはエラー文が親切なので,エラー文を読めば大抵のことは解決できるようになっています.
しかし,エラーが起きてもエラー文を一切読まない人が一定の割合で存在します. そのような人に理由を尋ねると最も多い理由は英語で書かれていること,2番目にどこを見ればいいのか分からないことを挙げます.
それほど難しい英語は使われていませんが,まず英語で書かれていても読んでみましょう. 英語が理解できなければ,機械翻訳にかけましょう.
pythonのエラー文は,基本的にエラー文の一番最初にスクリプトのエラーが発生している場所が書かれています.また,一番最後にどのようなエラーが起きているのかが書かれています. 複雑なプログラムになると,エラー全体を理解する必要が出てきますが,この講義で扱う程度の事例に関してはその2個所のみを読めばほとんどが解決します. ただし,検索結果は珠玉混合です, 正しい情報の取捨選択に関しては,情報入門の教科書などで復習しておきましょう.
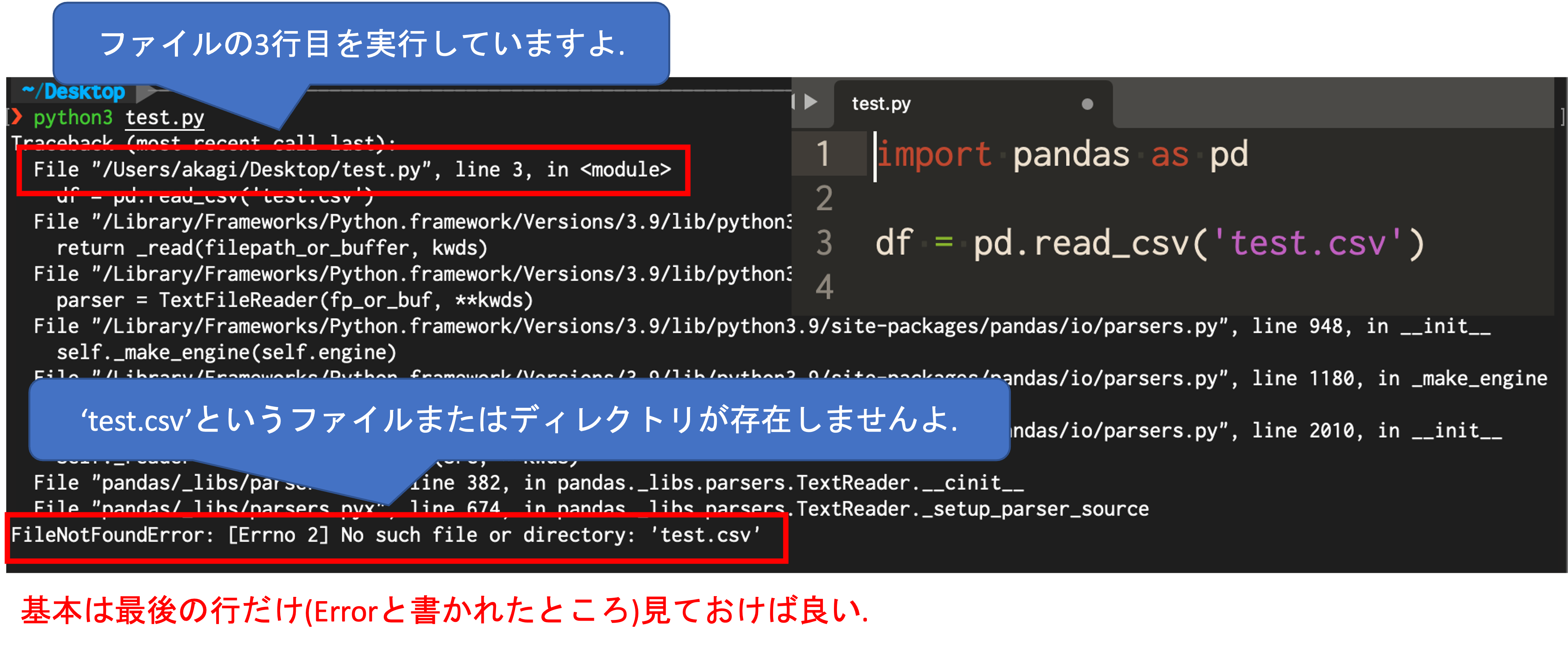
![]()
エラー文を読んでも意味が理解できない,あるいは対処方法が分からない場合には,エラー文の最後をそのまま検索しましょう. なお,Googleでは,""で囲うことで文章ごと検索(センテンス検索)できます. Pythonは日本語ユーザーも非常に多いため,エラー文 Pythonで検索すれば,大抵の問題は日本語で解決方法を読むことができます.
解決しない場合には,AND検索で情報を付加して,結果を絞りましょう. 検索条件に加えるべき情報の候補としては以下のようなものがあります.
OS (Windows, Mac)
Pythonのversion
利用しているライブラリ
やろうとしている作業
例えば,これから行うpandasを利用したファイルの読み込みにおいてNo such file or directoryというエラーが出た場合には pandas ファイル読み込み "No such file or directory" Windowsなどで検索してみましょう.
エラー文を読んで,Webで検索しても問題が解決しない場合には, 教員に聞いて下さい. 専門的な内容になるほど,日本語のページは少なくなります.また,新しい情報に関しては,日本語に翻訳されておらず公式のドキュメントなどを読む必要があります. それでも解決しない場合には, Pythonのコミュニティなどで質問をする必要があります. 最終的にはこれらを自分でできるようになる必要がありますが,最初は難しいと思います. 講義の教員は,それらを代替するためにいますので,教員に聞きましょう.
しかし,繰り返しになりますが,PCが使える,プログラミングができる,ということは自分で問題の解決策を調べて解決できるということです.したがって,まずは自分で調べて解決する癖をつけるようにしましょう.
エラーを体験してみよう
皆さんのプログラムが上手く動かない理由の圧倒的No1がスペルミス,タイプミスです. プログラミングの作業は,プログラムもコマンドも英語で記述します. プログラムは,1文字でも間違っていると上手く動かないので,しっかりとタイピングしましょう. 特にこれから行う作業で非常に多いスペルミスは以下のようなものです.
- 学生のスペルミス例
- Data → Date (なぜか3割くらいの学生が間違えます.)
- industry → indusutry, industly, indstry
- python → pyton, pyhon
- answer → anser, answere, ansewer
- salary → sarary, saraly, sarasly
- python –version → python version, python –vertion
スペルミスに対応するには注意するしかありません. 単純に英語の単語を覚えていない or タイピングミスが原因なので注意しましょう.英単語の意味がや綴がわからない場合には検索しましょう.
基本的にプログラミングにおいて無意味な英単語は利用していないので,意味を考えましょう(意味がない単語の例としてhoge,hugaなどは良く使いますが).特にDate (日付), Data(データ)などは頻出ですが, 単語の意味を考えればミスしづらいかと思います. また,エラー文を読めばどこが間違っているか教えてくれています.
エラー文にでてきた文字列’industry’や’Data’に該当する部分が間違っていないかチェックしましょう.
事例として,以下のプログラムの実行結果と,エラーについて見てみましょう. なお,プログラムの内容や詳細に関しては,このあとやるので理解できなくても問題ありません.
プログラムを実行するにあたって作業ディレクトリに以下のプログラムerror_sample.pyとプログラム内で読み込むデータdata/error_sample.csvが存在することを前提とします. ここでは,あくまで事例として紹介するので皆さんはデータとプログラムを用意する必要はありません.
やる必要はありませんが,同じ作業を試してみたい場合は,作業ディレクトリで以下のコマンドをコピーして実行しましょう
- Windowsの人
uv add pandas
echo "name,salary\ntaro,100" > data/error_sample.csv
echo "import pandas as pd\ndf = pd.read_csv('data/error_sample.csv') \nprint(df['salary'])" > error_sample.py- Macの人
uv add pandas
echo "name,salary\ntaro,100" > data/error_sample.csv
echo "import pandas as pd\ndf = pd.read_csv('data/error_sample.csv') \nprint(df['salary'])" > error_sample.pyファイルの構成が以下のようになっていれば問題ありません.
❯ ls
error_sample.py
❯ ls data
salary_data.csvそれぞれ,以下のようなファイルができているはずです(コメントは入っていません).
- error_sample.py
import pandas as pd
#dataフォルダにある,error_sample.csvファイルを読み込み
df = pd.read_csv('data/error_sample.csv')
#読み込んだファイルのsalary列を表示
print(df['salary'])- error_sample.csv
name,salary
taro,100このプログラムを実行してみると,error_sample.csvのsalary列の値が表示されます.
❯ python error_sample.py
0 100
Name: salary, dtype: int64プログラムを以下のように修正して実行してみます.
import pandas as pd
# error_sample.csvをarara_sample.csv に変更
df = pd.read_csv('data/arara_sample.csv')
print(df['salary'])以下のようなエラーが表示されます.
❯ python3 error_sample.py
Traceback (most recent call last):
File "/Users/akagi/Documents/Programs/Python/slds/error_sample.py", line 2, in <module>
df = pd.read_csv('data/arara_sample.csv')
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/pandas/io/parsers/readers.py", line 912, in read_csv
return _read(filepath_or_buffer, kwds)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/pandas/io/parsers/readers.py", line 577, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/pandas/io/parsers/readers.py", line 1407, in __init__
self._engine = self._make_engine(f, self.engine)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/pandas/io/parsers/readers.py", line 1661, in _make_engine
self.handles = get_handle(
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/pandas/io/common.py", line 859, in get_handle
handle = open(
FileNotFoundError: [Errno 2] No such file or directory: 'data/arara_sample.csv'先ほど解説したように最初の部分と,最後の部分だけを見てみましょう.
最初の部分ではエラーの発生場所を説明しています. このエラーは
line 2, in <module>のdf = pd.read_csv('data/arara_sample.csv')
部分で発生しています.先ほど変更を加えた2行目のファイル名の部分ですね.
最後の部分では,発生したエラーの中身について説明しています. エラーの詳細は
FileNotFoundError: [Errno 2] No such file or directory: 'data/arara_sample.csv'
であり,dataフォルダにarara_sample.csvというファイルがないという意味です.
プログラムのarara_sample.csvの部分を修正して,今度は,最後の行をエラーが出るように変更しています.
import pandas as pd
#dataフォルダにある,error_sample.csvファイルを読み込み
df = pd.read_csv('data/error_sample.csv')
#salaryをsararyに変更
print(df['sarary'])実行すると以下のようなエラーが発生します.
❯ python3 error_sample.py
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/pandas/core/indexes/base.py", line 3652, in get_loc
return self._engine.get_loc(casted_key)
File "pandas/_libs/index.pyx", line 147, in pandas._libs.index.IndexEngine.get_loc
File "pandas/_libs/index.pyx", line 176, in pandas._libs.index.IndexEngine.get_loc
File "pandas/_libs/hashtable_class_helper.pxi", line 7080, in pandas._libs.hashtable.PyObjectHashTable.get_item
File "pandas/_libs/hashtable_class_helper.pxi", line 7088, in pandas._libs.hashtable.PyObjectHashTable.get_item
KeyError: 'sarary'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/akagi/Documents/Programs/Python/slds/error_sample.py", line 3, in <module>
print(df['sarary'])
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/pandas/core/frame.py", line 3761, in __getitem__
indexer = self.columns.get_loc(key)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/pandas/core/indexes/base.py", line 3654, in get_loc
raise KeyError(key) from err
KeyError: 'sarary'今度のエラー文を見てみると,先ほど変更を加えた
File "/Users/akagi/Documents/Programs/Python/slds/error_sample.py", line 3, in <module>
の print(df['sarary'])でエラーが発生しており,エラーの内容は,sararyというKeyが存在しないという意味のKeyError: 'sarary'です. pandasのDataFrameにおけるKeyについてはまだ扱っていませんが,辞書型で発生するエラーと同様なので,辞書型を参考にして大まかな意味を掴みましょう.
>>> xs = {"name":"taro","salary":100}
>>> xs['salary']
100
>>> xs['sarary']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'sarary'上のコードでは,sararyというxsに存在しないkeyを呼び出したことでKeyErrorが発生しています.
- 演習
以下のプログラムをコピーして保存・実行し,エラーを確認しましょう. どのようなエラーが含まれているのか,エラー文を読んで修正し,説明してください.
- error_sample2.py
#Morningの"Good"部分を抽出したい.
#わざとエラーを含むプログラム
greetings = {"Morning":"Good Morning"
"Noon":"Hello"
,"Night":"Good Night"}
print(greeting["Morming"]["0":"4"]